
import tensorflow as tf ## pip install tensorflow-gpu
import cv2 ### pip install opencv-python
## pip install opencv-contrib-python fullpackage
import os
import matplotlib.pyplot as plt ## pip install matlplotlib
import numpy as np ## pip install numpy ## shift + enterimg_array = cv2.imread("Training/0/Training_314.jpg")
img_array.shape # rgb
(48, 48, 3)
print (img_array)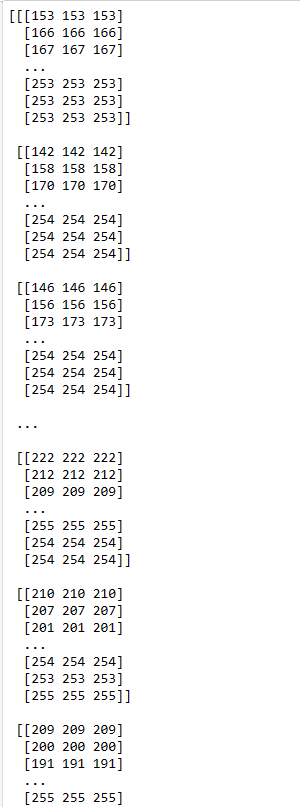
plt.imshow(img_array) ## BGR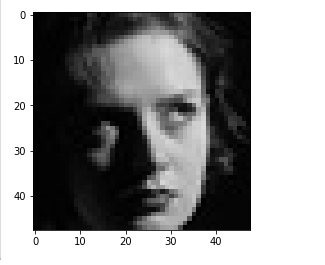
Datadirectory = "Training/" ## training dataset
Classes = ["0","1","2","3","4","5","6"] ## list of classes = > exact name of your folders
for category in Classes:
path = os.path.join(Datadirectory, category) ## //
for img in os.listdir(path):
img_array = cv2.imread(os.path.join(path,img))
#backtorgb = cv2.cvtColor(img_array,cv2.COLOR_GRAY2RGB)
plt.imshow(cv2.cvtColor(img_array, cv2.COLOR_BGR2RGB))
plt.show()
break
break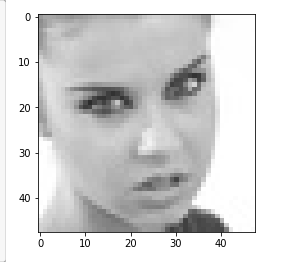
img_size= 224 ## ImageNet => 224 x 224
new_array= cv2.resize(img_array, (img_size,img_size))
plt.imshow(cv2.cvtColor(new_array, cv2.COLOR_BGR2RGB))
plt.show()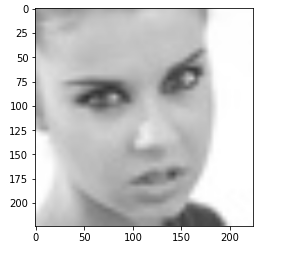
new_array.shape
(224, 224, 3)Read All The Image And Converting Them To Array
training_Data = [] ## data array
def create_training_Data():
for category in Classes:
path = os.path.join(Datadirectory, category)
class_num = Classes.index(category) ## 0 1, ## Label
for img in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path,img))
new_array= cv2.resize(img_array, (img_size,img_size))
training_Data.append([new_array,class_num])
except Exception as e:
passcreate_training_Data()
print(len(training_Data))
11568
temp = np.array(training_Data)
temp.shape
(11568, 2)import random
random.shuffle(training_Data)X = [] ## data /feature
y = [] ## label
for features,label in training_Data:
X.append(features)
y.append(label)
X = np.array(X).reshape(-1, img_size, img_size, 3) ## converting it to 4 dimension
X.shape
(11568, 224, 224, 3)
# normalize the data
X= X/255.0; ## we are normalizing it
type(y)
list
y[0]
3
Y= np.array(y)
Y.shape
(11568,)Deep Learning Model For Training-Transfer Learning
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layersmodel = tf.keras.applications.MobileNetV2() ## Pre-trained Model
model.summary()

Transfer Learning-Tuning ,Weights Will Start From Last Check Point
base_input = model.layers[0].input ## input
base_output = model.layers[-2].output
<tf.Tensor 'global_average_pooling2d/Identity:0' shape=(None, 1280) dtype=float32>
final_output = layers.Dense(128)(base_output) ## adding new layer, after the output of global pooling layer
final_ouput = layers.Activation('relu')(final_output) ## activation function
final_output = layers.Dense(64)(final_ouput)
final_ouput = layers.Activation('relu')(final_output)
final_output = layers.Dense(7,activation='softmax')(final_ouput) ## my classes are 07, classification layer
final_output ## ouput
<tf.Tensor 'dense_2/Identity:0' shape=(None, 7) dtype=float32>
new_model = keras.Model(inputs = base_input, outputs= final_output)
new_model.summary()
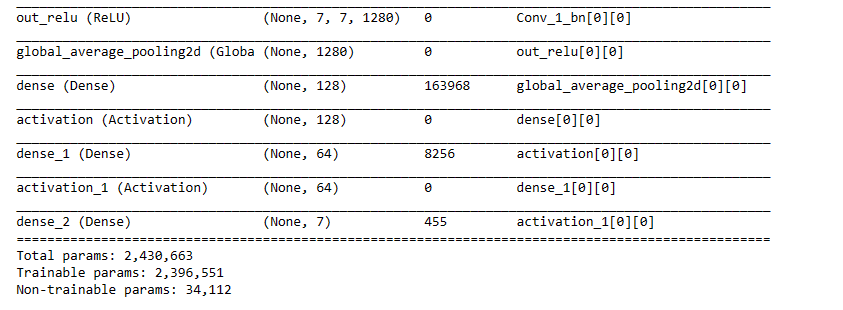
new_model.compile(loss="sparse_categorical_crossentropy", optimizer = "adam", metrics = ["accuracy"])
new_model.fit(X,Y, epochs = 25) ## training
new_model.save('Final_model_95p07.h5')
new_model = tf.keras.models.load_model('Final_model_95p07.h5')
frame = cv2.imread("surprised_man.jpg")
frame.shape
(410, 820, 3)
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))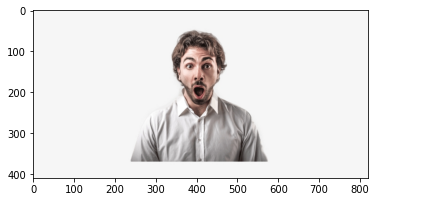
# we need face detection algorihtm (gray image )
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray.shape
(410, 820)faces = faceCascade.detectMultiScale(gray,1.1,4)
for x,y,w,h in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2) # BGR
facess = faceCascade.detectMultiScale(roi_gray)
if len(facess) == 0:
print("Face not detected")
else:
for (ex,ey,ew,eh) in facess:
face_roi = roi_color[ey: ey+eh, ex:ex + ew]
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))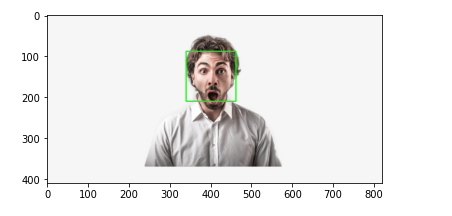
plt.imshow(cv2.cvtColor(face_roi, cv2.COLOR_BGR2RGB))
final_image =cv2.resize(face_roi, (224,224)) ##
final_image = np.expand_dims(final_image,axis =0) ## need fourth dimension
final_image=final_image/255.0 ## normalizing
Predictions =new_model.predict(final_image)
Predictions[0]
array([2.2529088e-05, 9.1614591e-09, 2.7516992e-06, 3.3497886e-07,
1.9450944e-07, 9.9997175e-01, 2.3757423e-06], dtype=float32)
np.argmax(Predictions)
5Realtime Video Demo
import cv2 ### pip install opencv-python
## pip install opencv-contrib-python fullpackage
#from deepface import DeepFace ## pip install deepface
path = "haarcascade_frontalface_default.xml"
font_scale = 1.5
font = cv2.FONT_HERSHEY_PLAIN
# set the rectangle background to white
rectangle_bgr = (255, 255, 255)
# make a black image
img = np.zeros((500, 500))
# set some text
text = "Some text in a box!"
# get the width and height of the text box
(text_width, text_height) = cv2.getTextSize(text, font, fontScale=font_scale, thickness=1)[0]
# set the text start position
text_offset_x = 10
text_offset_y = img.shape[0] - 25
# make the coords of the box with a small padding of two pixels
box_coords = ((text_offset_x, text_offset_y), (text_offset_x + text_width + 2, text_offset_y - text_height - 2))
cv2.rectangle(img, box_coords[0], box_coords[1], rectangle_bgr, cv2.FILLED)
cv2.putText(img, text, (text_offset_x, text_offset_y), font, fontScale=font_scale, color=(0, 0, 0), thickness=1)
cap = cv2.VideoCapture(1)
# Check if the webcam is opened correctly
if not cap.isOpened():
cap = cv2.VideoCapture(0)
if not cap.isOpened():
raise IOError("Cannot open webcam")
while True:
ret,frame = cap.read()
#eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades +'haarcascade_eye.xml')
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#print(faceCascade.empty())
faces = faceCascade.detectMultiScale(gray,1.1,4)
for x,y,w,h in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
facess = faceCascade.detectMultiScale(roi_gray)
if len(facess) == 0:
print("Face not detected")
else:
for (ex,ey,ew,eh) in facess:
face_roi = roi_color[ey: ey+eh, ex:ex + ew] ## cropping the face
final_image =cv2.resize(face_roi, (224,224))
final_image = np.expand_dims(final_image,axis =0) ## need fourth dimension
final_image=final_image/255.0
font = cv2.FONT_HERSHEY_SIMPLEX
Predictions = new_model.predict(final_image)
font_scale = 1.5
font = cv2.FONT_HERSHEY_PLAIN
if (np.argmax(Predictions)==0):
status = "Angry"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif (np.argmax(Predictions)==1):
status = "Disgust"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif (np.argmax(Predictions)==2):
status = "Fear"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif (np.argmax(Predictions)==3):
status = "Happy"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif (np.argmax(Predictions)==4):
status = "Sad"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif (np.argmax(Predictions)==5):
status = "Surprise"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
else:
status = "Neutral"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,255,0), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 255,0),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255,0))
#gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#print(faceCascade.empty())
#faces = faceCascade.detectMultiScale(gray,1.1,4)
# Draw a rectangle around the faces
#for(x, y, w, h) in faces:
# cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# Use putText() method for
# inserting text on video
cv2.imshow('Face Emotion Recognition',frame)
if cv2.waitKey(2) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()