
Re_Implementation Deep Emotion
Original Source of Deep Emotion
Original Source of Deep Emotion https://github.com/omarsayed7/Deep-Emotion
from __future__ import print_function
import argparse
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SubsetRandomSampler
from torchvision import transforms
import pdb
from data_loaders import Plain_Dataset, eval_data_dataloader
from deep_emotion import Deep_Emotion
from generate_data import Generate_data
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def Train(epochs,train_loader,val_loader,criterion,optmizer,device):
'''
Training Loop
'''
print("===================================Start Training===================================")
for e in range(epochs):
train_loss = 0
validation_loss = 0
train_correct = 0
val_correct = 0
# Train the model #
net.train()
for data, labels in train_loader:
data, labels = data.to(device), labels.to(device)
optmizer.zero_grad()
outputs = net(data)
loss = criterion(outputs,labels)
loss.backward()
optmizer.step()
train_loss += loss.item()
_, preds = torch.max(outputs,1)
train_correct += torch.sum(preds == labels.data)
#validate the model#
net.eval()
for data,labels in val_loader:
data, labels = data.to(device), labels.to(device)
val_outputs = net(data)
val_loss = criterion(val_outputs, labels)
validation_loss += val_loss.item()
_, val_preds = torch.max(val_outputs,1)
val_correct += torch.sum(val_preds == labels.data)
train_loss = train_loss/len(train_dataset)
train_acc = train_correct.double() / len(train_dataset)
validation_loss = validation_loss / len(validation_dataset)
val_acc = val_correct.double() / len(validation_dataset)
print('Epoch: {} \tTraining Loss: {:.8f} \tValidation Loss {:.8f} \tTraining Acuuarcy {:.3f}% \tValidation Acuuarcy {:.3f}%'
.format(e+1, train_loss,validation_loss,train_acc * 100, val_acc*100))
torch.save(net.state_dict(),'deep_emotion-{}-{}-{}.pt'.format(epochs,batchsize,lr))
print("===================================Training Finished===================================")
#if __name__ == '__main__':
#parser = argparse.ArgumentParser(description="Configuration of setup and training process")
#parser.add_argument('-s', '--setup', type=bool, help='setup the dataset for the first time')
#parser.add_argument('-d', '--data', type=str,required= True,
# help='data folder that contains data files that downloaded from kaggle (train.csv and test.csv)')
#parser.add_argument('-hparams', '--hyperparams', type=bool,
# help='True when changing the hyperparameters e.g (batch size, LR, num. of epochs)')
#parser.add_argument('-e', '--epochs', type= int, help= 'number of epochs')
#parser.add_argument('-lr', '--learning_rate', type= float, help= 'value of learning rate')
#parser.add_argument('-bs', '--batch_size', type= int, help= 'training/validation batch size')
#parser.add_argument('-t', '--train', type=bool, help='True when training')
#args = parser.parse_args()
#if args.setup :
## done separately by shanullah
#generate_dataset = Generate_data("data//")
#generate_dataset.split_test()
#generate_dataset.save_images()
#pdb.set_trace()
#generate_dataset.save_images('finaltest')
#generate_dataset.save_images('val')
epochs = 100
lr = 0.005
batchsize = 128
#pdb.set_trace() # if args.train:
net = Deep_Emotion() ## CREATE THE MODEL BY CALLING DEEPEMOTION.PY
net.to(device) ## MOVING IT TO GPU / cpu
print("Model archticture: ", net)
traincsv_file = 'data'+'/'+'train.csv'
validationcsv_file = 'data'+'/'+'val.csv'
train_img_dir = 'data'+'/'+'train/'
validation_img_dir = 'data'+'/'+'val/'
transformation= transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))])
train_dataset= Plain_Dataset(csv_file=traincsv_file, img_dir = train_img_dir, datatype = 'train', transform = transformation)
validation_dataset= Plain_Dataset(csv_file=validationcsv_file, img_dir = validation_img_dir, datatype = 'val', transform = transformation)
train_loader= DataLoader(train_dataset,batch_size=batchsize,shuffle = True,num_workers=0)
val_loader= DataLoader(validation_dataset,batch_size=batchsize,shuffle = True,num_workers=0)
criterion= nn.CrossEntropyLoss()
optmizer= optim.Adam(net.parameters(),lr= lr)
Train(epochs, train_loader, val_loader, criterion, optmizer, device)
Now After Training , Lets Save The Network By ShanUllah
torch.save(net.state_dict(), 'DeepEmotion_trained_by_shan2.pt')
net = Deep_Emotion()
net.load_state_dict(torch.load('DeepEmotion_trained_by_shan2.pt'))
net.to(device)
import cv2
import matplotlib.pyplot as plt
frame = cv2.imread('feared_man.jpg')
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))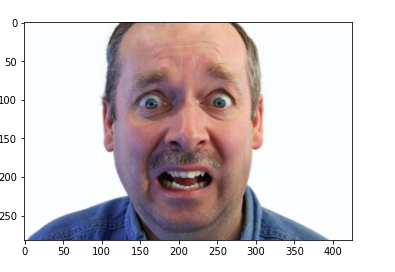
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_d
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,1.1,4)
for x,y,w,h in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
facess = faceCascade.detectMultiScale(roi_gray)
if len(facess) == 0:
print("Face not detected")
else:
for (ex,ey,ew,eh) in facess:
face_roi = roi_color[ey: ey+eh, ex:ex + ew]
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))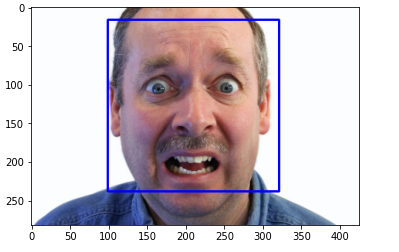
plt.imshow(face_roi)
face_roi.shape
(208, 208, 3)
gray = cv2.cvtColor(face_roi, cv2.COLOR_BGR2GRAY)
gray.shape
(208, 208)
final_image =cv2.resize(gray, (48,48))
final_image.shape
(48, 48)
final_image = np.expand_dims(final_image,axis =0) ## need fourth dimension
final_image.shape
(1, 48, 48)
final_image = np.expand_dims(final_image,axis =0) ## need fourth dimension
final_image.shape
(1, 1, 48, 48)
final_image=final_image/255.0 ## normalization step
dataa = torch.from_numpy(final_image)
dataa = dataa.type(torch.FloatTensor)
dataa = dataa.to(device)
outputs = net(dataa)
pred = F.softmax(outputs,dim=1)print(pred)
tensor([[0.1288, 0.0079, 0.4731, 0.2654, 0.0324, 0.0252, 0.0671]],
device='cuda:0', grad_fn=<SoftmaxBackward>)
print(torch.argmax(pred))
tensor(2, device='cuda:0')
index_pred = torch.argmax(pred)
if (index_pred == 5):
print('Just checking the values')Live Webcame Video
import cv2 ### pip install opencv-python
## pip install opencv-contrib-python fullpackage
#from deepface import DeepFace ## pip install deepface
path = "haarcascade_frontalface_default.xml"
font_scale = 1.5
font = cv2.FONT_HERSHEY_PLAIN
# set the rectangle background to white
rectangle_bgr = (255, 255, 255)
# make a black image
img = np.zeros((500, 500))
# set some text
text = "Some text in a box!"
# get the width and height of the text box
(text_width, text_height) = cv2.getTextSize(text, font, fontScale=font_scale, thickness=1)[0]
# set the text start position
text_offset_x = 10
text_offset_y = img.shape[0] - 25
# make the coords of the box with a small padding of two pixels
box_coords = ((text_offset_x, text_offset_y), (text_offset_x + text_width + 2, text_offset_y - text_height - 2))
cv2.rectangle(img, box_coords[0], box_coords[1], rectangle_bgr, cv2.FILLED)
cv2.putText(img, text, (text_offset_x, text_offset_y), font, fontScale=font_scale, color=(0, 0, 0), thickness=1)
cap = cv2.VideoCapture(1)
# Check if the webcam is opened correctly
if not cap.isOpened():
cap = cv2.VideoCapture(0)
if not cap.isOpened():
raise IOError("Cannot open webcam")
while True:
ret,frame = cap.read()
#eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades +'haarcascade_eye.xml')
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#print(faceCascade.empty())
faces = faceCascade.detectMultiScale(gray,1.1,4)
for x,y,w,h in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
facess = faceCascade.detectMultiScale(roi_gray)
if len(facess) == 0:
print("Face not detected")
else:
for (ex,ey,ew,eh) in facess:
face_roi = roi_color[ey: ey+eh, ex:ex + ew] ## cropping the face
graytemp = cv2.cvtColor(face_roi, cv2.COLOR_BGR2GRAY)
final_image =cv2.resize(graytemp, (48,48))
final_image = np.expand_dims(final_image,axis =0) ##add thir dimension
final_image = np.expand_dims(final_image,axis =0) ## add fourth dimension
final_image=final_image/255.0 # normalization
dataa = torch.from_numpy(final_image)
dataa = dataa.type(torch.FloatTensor)
dataa = dataa.to(device)
outputs = net(dataa)
Pred = F.softmax(outputs,dim=1)
Predictions = torch.argmax(Pred)
print(Predictions)
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1.5
font = cv2.FONT_HERSHEY_PLAIN
if ((Predictions)==0):
status = "Angry"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif ((Predictions)==1):
status = "Disgust"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif ((Predictions)==2):
status = "Fear"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif ((Predictions)==3):
status = "Happy"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif ((Predictions)==4):
status = "Sad"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
elif ((Predictions)==5):
status = "Surprise"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 0, 255),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255))
else:
status = "Neutral"
x1,y1,w1,h1 = 0,0,175,75
# Draw black background rectangle
cv2.rectangle(frame, (x1, x1), (x1 + w1, y1 + h1), (0,0,0), -1)
# Add text
cv2.putText(frame, status, (x1 + int(w1/10),y1 + int(h1/2)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,255,0), 2)
cv2.putText(frame,status,(100, 150),font, 3,(0, 255,0),2,cv2.LINE_4)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255,0))
#gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#print(faceCascade.empty())
#faces = faceCascade.detectMultiScale(gray,1.1,4)
# Draw a rectangle around the faces
#for(x, y, w, h) in faces:
# cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# Use putText() method for
# inserting text on video
cv2.imshow('Face Emotion Recognition',frame)
if cv2.waitKey(2) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()dataset = Plain_Dataset(csv_file='data'+'/finaltest.csv',img_dir = 'data' +'/'+'finaltest/',datatype = 'finaltest',transform = transformation)
test_loader = DataLoader(dataset,batch_size=64,num_workers=0)#Model Evaluation on test data
classes = ('Angry', 'Disgust', 'Fear', 'Happy','Sad', 'Surprise', 'Neutral')
total = []
with torch.no_grad():
for data, labels in test_loader:
data, labels = data.to(device), labels.to(device)
outputs = net(data)
pred = F.softmax(outputs,dim=1)
classs = torch.argmax(pred,1)
wrong = torch.where(classs != labels,torch.tensor([1.]).cuda(),torch.tensor([0.]).cuda())
acc = 1- (torch.sum(wrong) / 64)
total.append(acc.item())
print('Accuracy of the network on the test images: %d %%' % (100 * np.mean(total)))
Accuracy of the network on the test images: 51 %
data[0].shape
torch.Size([1, 48, 48])Accuracy Is Not Exactly The Once Which Is Claimed
#generate_dataset.save_images('finaltest')
100%|█████████████████████████████████████████████████████████████████████████████| 3589/3589 [00:03<00:00, 899.87it/s]
Done saving data///finaltest data
#generate_dataset.save_images('val')
100%|█████████████████████████████████████████████████████████████████████████████| 3590/3590 [00:03<00:00, 937.15it/s]
Done saving data///val data